Обычно поисковая система представляет собой комплекс из нескольких компьютеров, каждый из которых выполняет свою часть работы. Например, «Апорт-2000» работает на 12 компьютерах под управлением Windows NT, Яndex — на шести, а Rambler — на трех Unix-серверах.
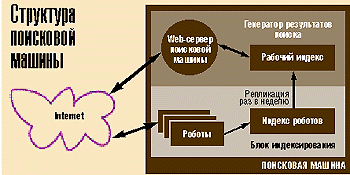
В поисковой системе должны быть роботы, которые получают страницы из Internet, анализируют их и подготавливают своеобразную выжимку информации, которая называется индексом поисковой системы. В индексе хранится информация, на основе которой поисковая система выдает ответы на запросы пользователей. Роботы, как правило, работают постоянно, накапливая информацию о расположении файлов в Internet, однако для пользователей она становиться доступной только через некоторое время. Полная и единовременная смена индекса необходима для корректной работы механизмов поиска и ранжирования документов.
Анализ содержания Internet — процесс непростой, и обеспечить непрерывную обработку его результатов бывает сложно. Обычно используется следующая схема: робот работает непрерывно, а потом в определенный момент полученные результаты становятся доступны пользователю.
Информация в поисковой системе сначала накапливается и индексируется, а затем загружается на машины, которые выдают результаты пользователям. Накопленная роботом информация перегружается в генератор выдачи в определенные моменты времени. Период обновления индекса генератора у трех основных русскоязычных поисковых машин — Яndex, Rambler и «Апорт» — неделя. При этом Яndex и Rambler обновляют общедоступный индекс в выходные, а «Апорт» — в рабочие дни. Поэтому, зарегистрировав свой ресурс в поисковой машине, не следует сразу же искать ссылку на него в результатах поиска — он станет доступным только тогда, когда будет сменен индекс генератора. В идеале за время, которое проходит от одной смены индекса до другой, поисковая система должна заново просмотреть и проанализировать все накопленные в ней локаторы ресурсов (URL). Но так бывает не всегда, и тогда в результатах выдачи поисковой машины появляются устаревшие или неправильные ссылки.
Есть, конечно, ресурсы, которые обновляются каждый день, например Internet-газеты или ленты новостей информационных агентств. Использовать для поиска по ним существующие поисковые машины нельзя — информация в принципе обновляется быстрее, чем индексируется. Вероятно, поиск по новостным серверам должен выполняться отдельно, поскольку работа с ними сильно отличается от поиска в Internet вообще, и, вероятно, должна быть согласована с авторами ресурсов. Сейчас таких служб нет, но, возможно, они появятся.
Есть одно важное правило работы с поисковыми машинами — использование файла robots.txt, который располагается в корневом каталоге сервера. Этот файл описывает для поискового робота структуру сервера и указывает ему разрешенные и запрещенные для индексирования HTML-документы. Если в тексте встречаются элементы, которые не нужно индексировать, можно использовать теги <index> и </noindex>.
Все российские поисковые системы используют файл robots.txt и указанные выше теги при анализе содержания сервера. Причем если известно имя робота конкретной поисковой системы, то можно установить доступ к документам сервера только для него.Следует отметить, что для любой уникальной страницы найдется такой запрос, при котором она будет первой в результатах выдачи поисковой машины. Таким образом, для привлечения внимания к ресурсу достаточно сделать его уникальным.
Нужно отметить, что классические поисковые машины работают в основном с HTML-страницами. Но редко кто из владельцев серверов хранит большие объемы информации в HTML, — скорее всего, вся информация содержится в какой-либо базе данных. Базы данных, размещенные в Web, не всегда доступны путем последовательного просмотра, ведь они очень часто используют параметры, которые поисковая система не может самостоятельно генерировать. Поэтому ни одна поисковая система не анализирует странички с параметрами (те, в которых есть знак вопроса).
Другой проблемой являются серверы, для каждого HTML-документа генерирующие свой уникальный URL. Примером такого Web-сервера является Lotus Domino, при индексировании которого поисковая машина может попросту зациклиться. При использовании в своем Web-сервере базы данных необходимо учитывать его возможное индексирование какой-либо поисковой машиной. Например, где-нибудь на сервере публиковать его полную структуру, со ссылками на все хранящиеся в базе записи. Вообще же, можно предусмотреть в структуре Web-сервера специальные страницы для поисковых систем, через которые робот быстро и эффективно доберется до всех документов узла.